TL;DR – Move Kubernetes volumes from legacy storage to Pure Storage.
So you have an amazing new Pure Storage array in the datacenter or in public cloud. The Container Storage Interface doesn’t provide a built in way to migrate data between backend devices. I previously blogged about a few ways to clone and migrate data between clusters but the data has to already be located on a Pure FlashArray.
Lately, Pure has been working with a new partner Kasten. While more is yet to come. Check out this demo (just 5:30) and see just how easy it is to move PVC’s while maintaining the config of the rest of the k8s application.
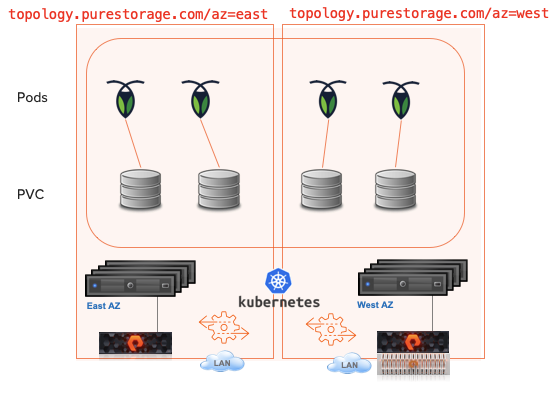
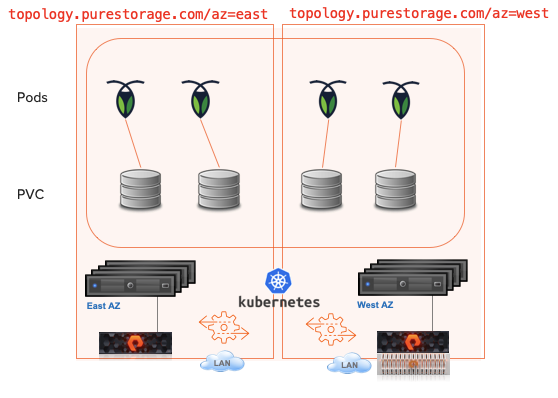
This demo used EKS in AWS for the Kubernetes cluster.
- Application initially installed using a PVC for MySQL on EBS.
- Kasten is used to backup the entire state of the app with the PVC to S3. This target could be a FlashBlade in your datacenter.
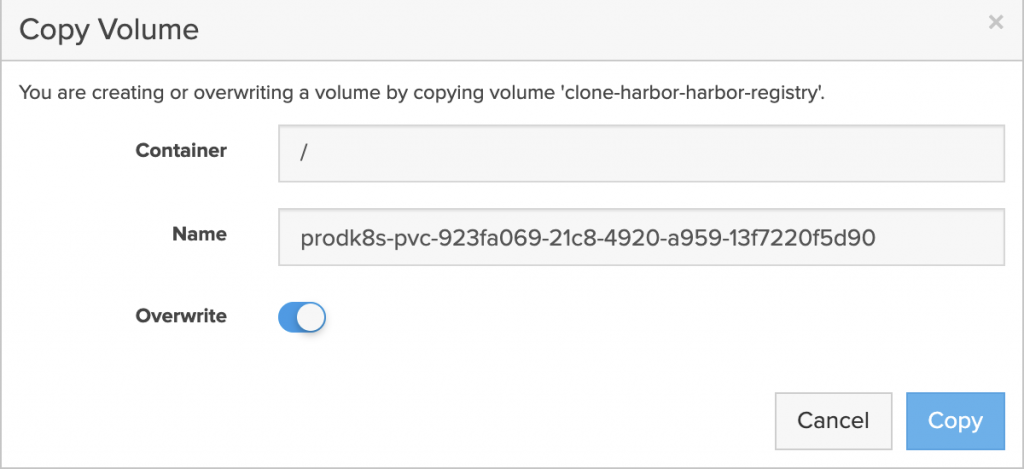
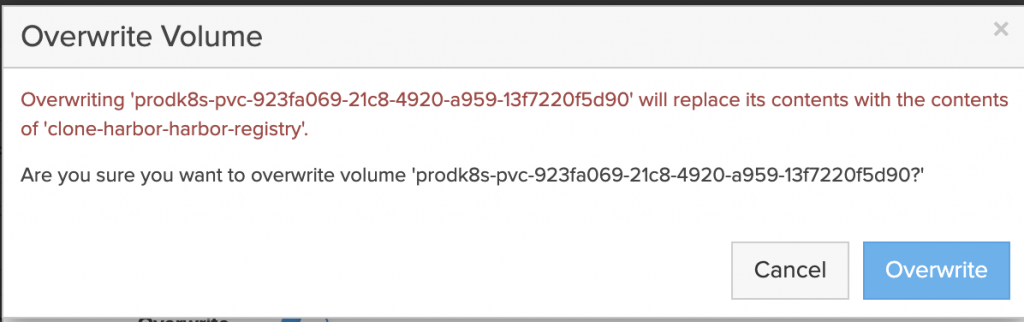
- The application is restored to the same namespace but a Kasten Transform is used to convert the PVC to the “pure-block” StorageClass.
- Application is live and using PSO for the storage on Cloud Block Store.

Why
Like the book says, “End with why”. Ok maybe it doesn’t actually say that. Let’s answer the “why should I do this?”
First: Why move EBS to CBS
This PVC is 10GB on EBS. At this point in time it consumes about 30MB. How much does the AWS bill on the 10GB EBS volume? 10GB. On Cloud Block Store this data is reduced (compressed and deduped) and thin provisioned. How much is on the CBS? 3MB in this case. Does this make sense for 1 or 2 volumes? Nope. If your CIO has stated “move it all to the cloud!” This can be a significant savings on overall storage cost.
Second: Why move from (some other thing) to Pure?
I am biased to PSO for Kubernetes so I will start there and then give a few bullets of why Pure, but this isn’t the sales pitch blog. Pure Service Orchestrator allows you a simple single line to install and begin getting storage on demand for your container clusters. One customer says, “It just works, we kind of forget it is there.” and another commented, “I want 100GB of storage for my app, and everything else is automated for me.”
Why Pure?
- Efficiency – Get more out of the all-flash, higher dedupe with no performance penalty does matter.
- Availability – 6×9’s uptime measured across our customer base, not an array in a validation lab. Actual customers love us.
- Evergreen – never. buy. the same TB/GB/MB again.