Getting Started with Portworx 2.8 and the FlashArray and FlashBlade
Last week Portworx 2.8 went GA, with it new support for Tanzu TKGs TKGm (We supported PKS/TKGi for a long time), but also Support for Cloud Drives for FlashArray and Direct Access for FlashBlade. It also simplified the installation of Portworx with Tanzu from this earlier version.
FlashArray Volumes for Portworx
Portworx will automate creating a storage pool from volumes provisioned from the FlashArray. This is done for your during the install, you may specify the size of the volumes in the spec generator at https://central.portworx.com
Process to install
NOTE as of 8/4/21: This feature is in Tech Preview (contact me if you want to run in Production)
Create the px-pure-secret from the pure.json file
Generate your Portworx Cluster spec from https://central.portworx.com
Install the PX-Operator (command at the end of the spec generator).
Install the Portworx Storage Cluster
https://docs.portworx.com/reference/pure-json-reference/ Also look that the pure.json reference in order to get the API key and token in a secret for you to use with Portworx. The installation of Portworx detects this Kubernetes secret and uses that information to provision drives from the array. Check out the youtube demo:
Remember the secret must be called px-pure-secret and be in the namespace that you install Portworx.
Select Pure FlashArray
2. Generate the spec for the Portworx Cluster.
3. Install the PX-Operator – I suggest using what you get from the Spec generator online or down to a local file.
kubectl apply -f pxoperator.yaml
4. Install the Storage Cluster
kubectl apply -f px-spec.yaml
For FlashBlade!
Also included in the pure.json is the API Token and IP information for my FlashBlade. Since the FlashBlade runs NFS the K8s node mounts it directly. We call with Direct Attach and allows you to leverage your FlashBlade for data that may exist outside of the PX-Cluster. Watch the demo to see it in action. Create a StorageClass for FlashBlade and a PVC using that class. Portworx automates the rest. More info: https://docs.portworx.com/portworx-install-with-kubernetes/storage-operations/create-pvcs/pure-flashblade/
OpenStack administrators have to deal with a lot, including, potentially, many different storage backends in Cinder. Pure Storage now make it easier for them to see what is going on with their Pure FlashArray backends.
With so many different storage backends available to OpenStack Cinder administrators who want to understand how their Cinder backends are being utilized have, historically, had to log on to every backend and therefore need to be conversant with all the vendor-specific storage frontends they have in their environment. The OpenStack Horizon GUI is complex enough, without having to learn other GUIs.
Additionally, OpenStack tenants who are interested in their storage utilization and performance have no way of getting this information without raising internal tickets for their storage support teams – and we all know how long those can take to get answered…
Well, Pure Storage has tried to alleviate these problems by providing an OpenStack plugin for Horizon.
From an OpenStack administrators perspective give a high level view of the utilization levels of Pure Storage FlashArrays configured as Cinder backends, and the tenants it will provide real-time volume utilization and performance information.
So what do you get with the plugin?
For the Administrator, there is a new Horizon panel in the Admin / System section called Pure Storage.
In this new panel you get a simple view of your FlashArray backends in the well-known Horizon format. Interesting information such as overall data reduction rates (with and without thin-provisioning included) is given as well as utilization levels against array limits – useful to see for both OpenStack dedicated arrays and those that have multiple workloads.
If you select the actual array name in the table a new browser tab will open at the actual FlashArray GUI if you want to log in directly, however if you select the Cinder Name in the table you get a detailed view of the array in Horizon providing more capacity and performance information.
The Overview pie charts in this detailed view show the array specific limits for this array, so will be different depending on the Purity version of the FlashArray.
If you aren’t an Administrator and just a regular Tenant in OpenStack, you won’t see these options available to you, but you will be able to get more detail on any volumes are using that are backed by Pure Storage FlashArrays.
By selecting a Pure backed volume in your Volumes page you will get enhanced detail information around the utilization, data reduction and performance of your volume. This data is current, so a refresh of the page will update these statistics.
Hopefully, OpenStack Admins and Users will find this new Horizon plugin useful.
To get more details on installing and configuring check out this GitHub repo.
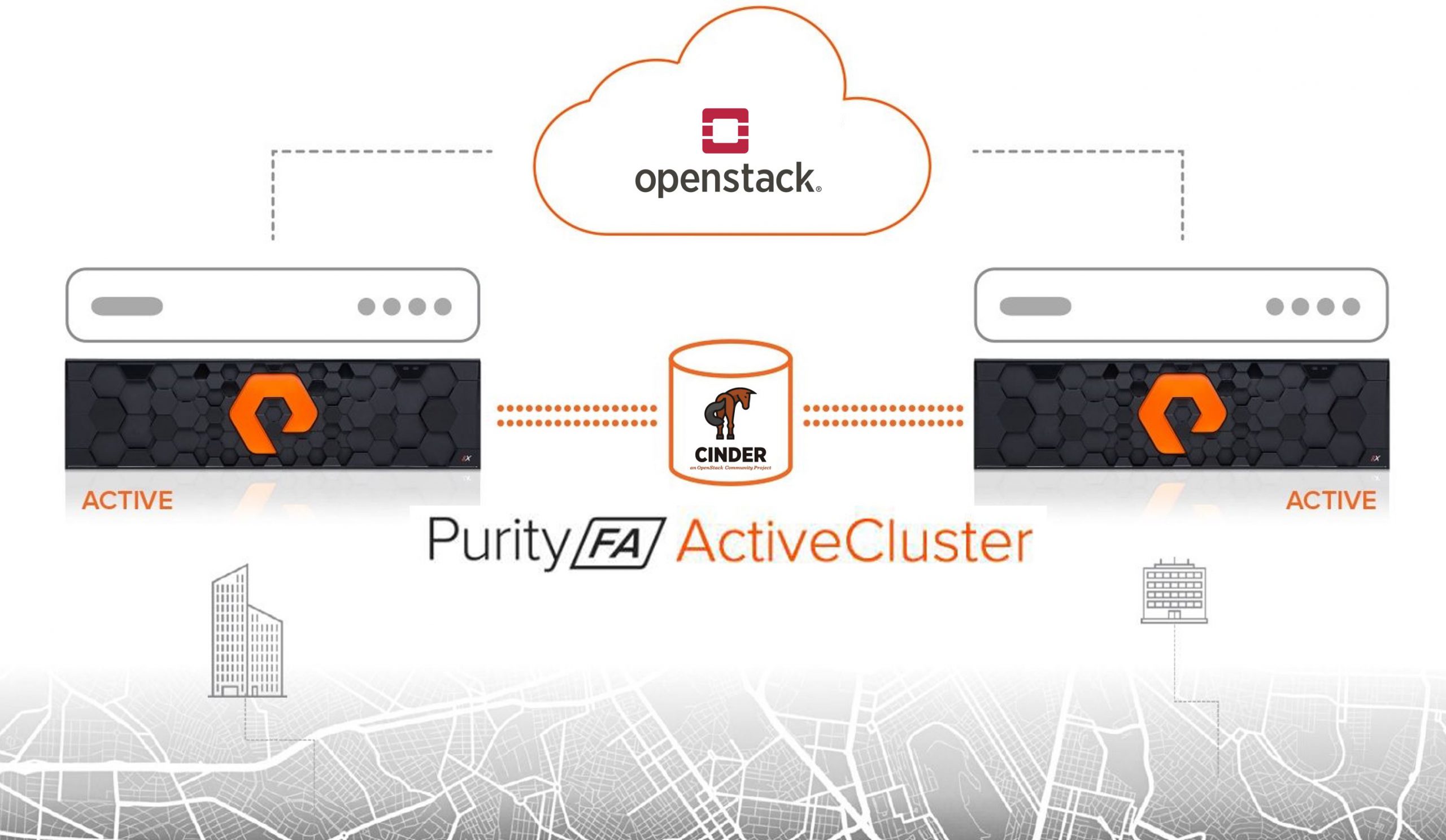
Since the Mitaka release of OpenStack, the Pure Storage Cinder driver has supported Cinder replication, although this first iteration only supported asynchronous replication.
The Rocky release of OpenStack saw Pure’s Cinder driver support synchronous replication by integrating our ActiveCluster feature from the FlashArray.
This synchronous replication automatically created an ActiveCluster pod on the paired FlashArrays called cinder-pod. A pretty obvious name I would say.
While this provided a seamless integration for OpenStack users to create a synchronously replicated volume using a correctly configured volume type, there was one small limitation. ActiveCluster pods were limited to 3000 volumes.
Now you might think that is more than enough volumes for any single ActiveCluster environment. I certainly did until I received a request to be able to support 6000 volumes synchronously replicated.
After some scratching of my head, I remembered that from the OpenStack Stein release of the Pure Cinder driver there is an undocumented (well, not very well documented) parameter that allows the name of the ActiveCluster pod to be customizable and that gave me an idea….
Can you configure Cinder to use the same backend as separate stanzas in the Cinder config file with different parameters?
It turns out the answer is Yes.
So, here’s how to enable your Pure FlashArray Cinder driver to use a single ActiveCluster pair of FlashArrays to allow for 6000 synchronously replicated volumes.
First, we need to edit the cinder.conf file and create two different stanzas for the same array that is configured in an ActiveCluster pair and ensure we have enabled both of these backends:
If we look at the two stanzas, the only difference is that the pure_replication_pod_name is different. I have also set the volume_backend_name to be the same for both configurations. There is a reason for this I will cover later.
After altering the configuration file, make sure to restart your Cinder Volume service to implement the changes.
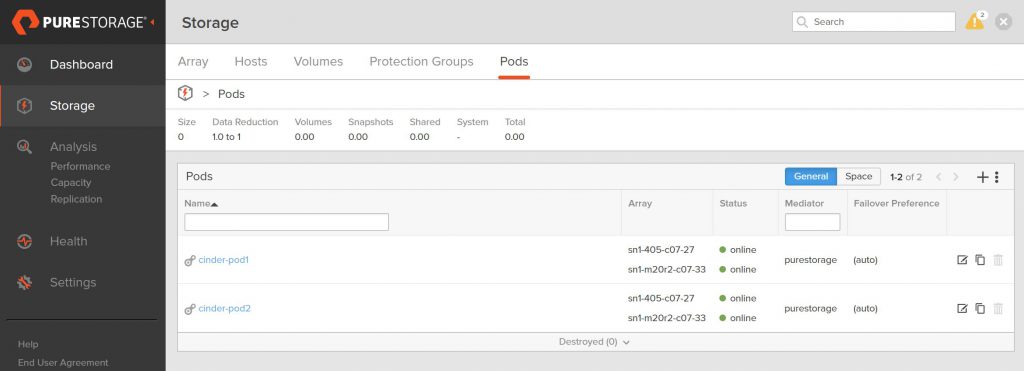
After restarting the cinder-volume service, you will see on the FlashArray that two ActiveCluster pods now exist with the names defined in the configuration file.
This is the first step.
Now we need to enable volume types to be able to use these pods and also to load-balance across the two pods – why load-balance? It just seems to make more sense to make volumes evenly utilize the pods, but there is no specific reason for doing this. If you wanted to use each pod separately, then you would need to set a different volume_backend_name in the Cinder configuration file for each array stanza.
When creating a volume type to use synchronous replication you need to set some specific extra_specs in the type definition. These are the commands to use:
openstack volume type create pure-repl
openstack volume type set --property replication_type=’<in> sync’ pure_repl
openstack volume type set --property replication_enabled=’<is> True’ pure_repl
openstack volume type set --property volume_backend_name=’pure’ pure_repl
The final configuration of the volume type would now look something like this:
openstack volume type show pure-repl
+--------------------+-------------------------------------------------------------------------------------------+
| Field | Value |
+--------------------+-------------------------------------------------------------------------------------------+
| access_project_ids | None |
| description | None |
| id | 2b6fe658-5bbf-405c-a0b6-c9ac23801617 |
| is_public | True |
| name | pure-repl |
| properties | replication_enabled='<is> True', replication_type='<in> sync', volume_backend_name='pure' |
| qos_specs_id | None |
+--------------------+-------------------------------------------------------------------------------------------+
Now, all we need to do is use the volume type when creating
our Cinder volumes.
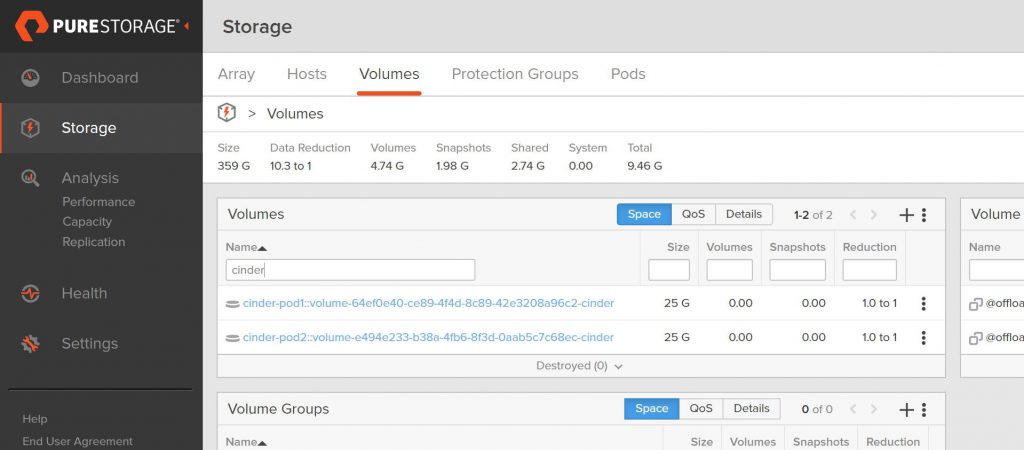
Let’s create two volumes and see how they appear on the FlashArray:
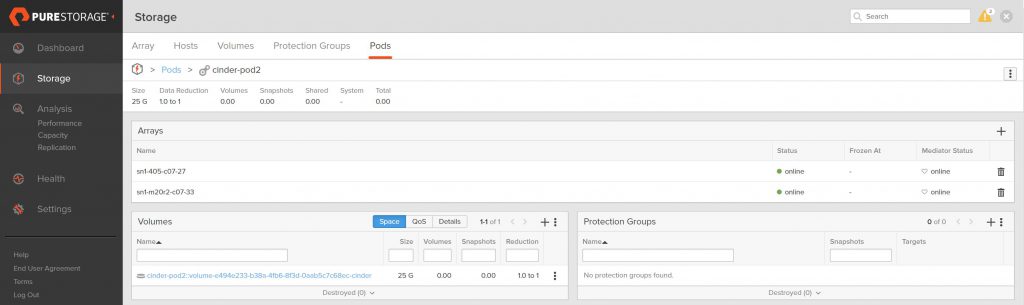
Looking at the FlashArray, we can see the two volumes we just created (I am filtering the volume name on cinder just so you only see the OpenStack related volumes on this array)
The volume naming convention we use at Pure shows that these
volumes are in a pod due to the double colon (::)
in the name and the pod name for each volume is cinder-pod1
and cinder-pod2 respectively.
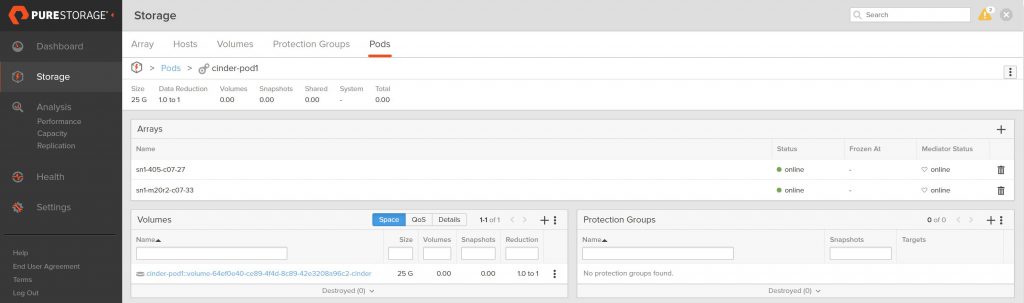
The view of each pod also shows only one volume in each.
If you didn’t want to load-balance across the pods and needed the flexibility to specify the pod a volume exists in, all I need do is set the volume_backend_name to be different in the configuration file array stanzas and then create two volume types. Each would point to the different volume_backend_name setting.
September 22 at 1:00pm Eastern time Pure Storage and VMware will be highlighting the results of ESG Lab Validation paper. The study on consolidating workloads with VMware and Pure Storage used a single FlashArray //m50 and deployed five virtualized mission-critical workloads VMware Horizon View, Microsoft Exchange Server, Microsoft SQL Server (OLTP), Microsoft SQL Server (data warehouse) and Oracle (OLTP). While I won’t steal all the thunder it is good to note that all of this was run with zero tuning on the applications. Want out of the business of tweaking and tuning everything in order to get just a little more performance from your application? Problem Solved. Plus check out the FlashArray and the consistent performance even during failures.
Tier 1 workloads in 3u of Awesomeness
You can see in the screenshot the results of running tier one application on an array made to withstand real-world ups and downs of the datacenter. Things happen to hardware and software even, but it is good to see the applications still doing great. We always tell customers, it is not how fast the array is in a pristine benchmark, but how does it respond when things are not going well, when controller loses power or a drive (or two) fails. That is what sets Pure Storage apart (that and data reduction and real Evergreen Storage).
Small note: Another proven environment with near 32k block sizes. This one hung out between 20k and 32k, don’t fall for 4k or 8k nonsense benchmarks. When the blocks hit the array from VMware this is just what we see.
A few months back I posted a powershell script to post Pure Storage data directly into VMware vCenter Operations Manager (now called vRealize Operations). Inspiration hit me like a brick when a big customer of mine said, “Do you have a plugin for Splunk?”
He already wrote some scripts in python to pull data from our REST API. He just said, “Sure wish I didn’t have to do this myself.” I took the hint. Now I am not a python person, so I did the best I could with the tools I have.
You will notice that the script is very similar to the one I wrote for vCOPS. That is because open REST API’s rock, if you don’t have one for your product you are wrong. 🙂
Like before I schedule this as a task to run every 5 minutes. That seems to not explode the tiny Splunk VM I am running in VMware Fusion to test this out.
Dashboards. Check.
Some very basic Dashboards I created. I am not a Splunk ninja, perhaps you know one? I am sure people that have done this for a while can pull much better visuals out of this data.
Pivot Table
Stats from a Lab array some Averages computed by Splunk.
Gauge Report of Max Latency (that is micro seconds)
A 1000 of these is 1 millisecond 🙂 pretty nice.
From Wikipedia
A microsecond is an SI unit of time equal to one millionth (0.000001 or 10−6 or 1/1,000,000) of a second. Its symbol is μs. One microsecond is to one second as one second is to 11.574 days. A microsecond is equal to 1000 nanoseconds or 1/1,000 milliseconds.
Even if everything else didn’t help you at least you learned that today. Right?