Kubecon and VMware Explore are coming up. One of our most popular sessions from our VMware Explore(and VMworld) is the Stretched Cluster for VMware/vVols. Now, you all may notice that SRM and other DR solutions do not work with Tanzu, but I want all of you to know that PX-DR Sync or Metro-DR is supported for Tanzu. This allows you to have ZERO RPO when failing Stateful workloads from 1 cluster to another. This can be from one vSphere cluster to another each running TKG.
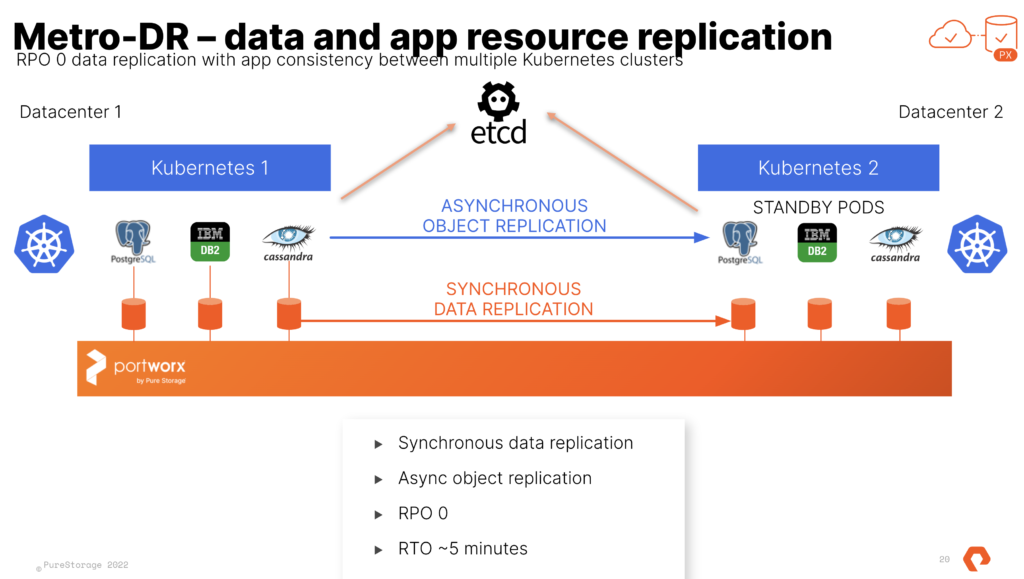
Metro-DR
More information for how to setup Sync-DR with Tanzu can be found here in our docs page.
Pay close attention to the docs as Tanzu has some special steps in the setup because of the way the Cloud Drives are created and managed with raw CNS volumes.
This is done with a shared etcd between the two distinct TKG clusters. That etcd can run at a third site where you would run the “witness node”. I run this in a standalone admin k8s cluster that runs all my internal services like etcd, externaldns, harbor and more. Just so you know this etcd is used by Portworx Enterprise only and is not the one used by k8s.
Slightly better image of Metro-DR
At the end of the process you have 2 TKG Clusters and 1 Portworx Cluster. We use Async schedules to copy the objects between clusters. The data is synchronously copied between nodes only limited by the latency. (Max for sync-dr is 10ms). This means the deployment for Postgres or Cassandra in the picture above is copied on a schedule and the non-live or target cluster is scaled to 0 replicas. The RPO is 0 since the data is copied instantly, the RTO is based on how fast you can spin up the replicas on the target.
Even though Portworx Enterprise and Metro-DR works with any storage target supported by Tanzu (VSAN, NFS Datastores, VMFS Datastores, other vVOls). The SPBM and vVols integrations from Pure Storage with the FlashArray are the most used anywhere. The effort for the integration and collaboration betweet Pure and VMware Engineering is amazing. Cody Hosterman and his team have done some amazing things. Metro-DR works great with Pure vVols and is the perfect cloud-native compliment to your stretched vVols VM’s using FlashArray ActiveCluster. If you are interested in using both together let your Pure Storage team know or send me a message on the twitter and I will track them down for you.
So I am a week or so late but the latest update of Portworx Data Services now officially supports Tanzu. Now I say officially since it did kind of work the whole time. I just can’t declare our support to the world until it passes all the tests from Engineering. So go ahead. The easiest way to get a Database Platform as a Service can now be built on you Tanzu clusters. Go to https://central.portworx.com and contact your local PX team to get access.
The key here is to deploy Cassandra via PDS then get the server connection names from PDS. Each step is explained in the repo. Go over there and fork or clone the repo or just use my settings. A quick summary though (it is really this easy).
Deploy Cassandra to your Target in PDS.
Edit the env-secret.yaml file to match your deployment.
Apply the secret. kubectl -n namespace apply -f env-secret.yaml
Apply the deployment. kubectl -n namespace apply -f worker.yaml
Check the database in the Cassandra pod. kubectl -n namespace exec -it cas-pod — bash
Use cqlsh to check the table the app creates.
That is it pretty easy and it creates a lot of records in the database. You could also scale it up in order to test connections from many sources. I hope this helps you quickly use PDS and if you have any updates or changes to me repo please submit a PR.
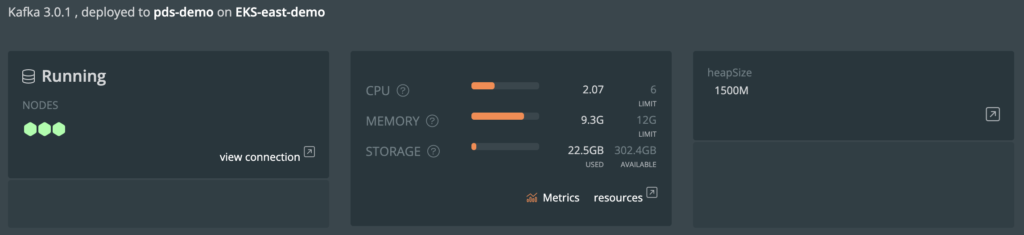
With the GA of Portworx Data Services I needed a way to connect some test applications with Apache Kafka. Kafka is one of the most asked for Data Services in PDS. Deploying Kafka is very easy with PDS but I wanted to show how it easy it was for a data team to connect their application to Kafka in PDS. I was able to find a kafka-python library, so I started working on a couple of things.
A python script to create some kind of load on Kafka.
Containerize it, so I can make it easy and repeatable.
Create the kubernetes deployments so it is quick and easy.
See the repo for the steps on setting up the secret and deployments in K8s to use with your PDS Kafka, honestly it should work with any Kafka deployment where you have the connection service, username and password.
A quick demo of it all in action
Check out the youtube demo I did above to see it all in action.
Graph DB solution Neo4j is popular with Data Scientists and Data Architects trying to make connections of the nodes and relationships. Neo4j is able to do memory management other in memory operations to allow for efficiency and performance. All of that data needs to eventual persist to a data management platform. This is why I was first asked about Neo4j.
Some cool nodes
There are Community and Enterprise Editions like most software solutions these days and the robust enterprise type functions land in the Enterprise Edition. Things like RBAC and much higher scale.
Neo4j provides a repo of Helm charts and some helpful documentation on running the Graph Database in Kubernetes. Unfortunately, the instructions stop short of many of the K8s flavors supported by the cloud and on premises solutions. Pre-provisioning cloud disks might be great for a point solution of a single app. Most of my interactions with the people running k8s in production are building Platform as a Service (PaaS) or Database as a Service (DBaaS). Nearly all at least want the option of building these solutions to be hybrid or multi cloud capable. Additionally, DR and Backup are requirements to run in any environment that values their data and staying in business.
Portworx in 20 seconds
Portworx is a data platform that allows stateful applications such as Neo4j to run on an Cloud, on Premises Hardware on any K8s Distribution. It was built from the very beginning to run as a container for containers. </end commercial>
In this blog post I want to enhance and clarify the documentation for the Neo4j helm chart so that you can easily run the community or Enterprise Editions in your K8s deployment.
As with any database Neo4j will benefit greatly from running the persistence on Flash. All of my testing was done with a Pure Storage FlashArray.
Step 1
Already have K8s and Portworx installed. I used Portworx 2.9.1.1 and Vanilla K8s 1.22. Also already have Helm installed. Note: The helm chart was giving me trouble until I updated helm to version 3.8.x
neo4j:
resources:
cpu: "0.5"
memory: "2Gi"
# Uncomment to set the initial password
#password: "my-initial-password"
# Uncomment to use enterprise edition
#edition: "enterprise"
#acceptLicenseAgreement: "yes"
volumes:
data:
mode: "dynamic"
# Only used if mode is set to "dynamic"
# Dynamic provisioning using the provided storageClass
dynamic:
storageClassName: "neo4j"
accessModes:
- ReadWriteOnce
requests:
storage: 100Gi
Cluster values.yaml
node[0-x]values-cluster.yaml
Why do I say 0-x? Well neo4j requires a helm release for each core cluster node (read more detail in the neo4j helm docs). Each file for now is the same. Note: neo4j is an in memory database. 2Gi ram is great for the lab, but for really analytics use I would hope to use much more memory.
neo4j:
name: "my-cluster"
resources:
cpu: "0.5"
memory: "2Gi"
password: "my-password"
acceptLicenseAgreement: "yes"
volumes:
data:
mode: "dynamic"
# Only used if mode is set to "dynamic"
# Dynamic provisioning using the provided storageClass
dynamic:
storageClassName: "neo4j"
accessModes:
- ReadWriteOnce
requests:
storage: 100Gi
Read Replica values
Create another helm yaml file here is rr1-values-cluster.yaml
neo4j:
name: "my-cluster"
resources:
cpu: "0.5"
memory: "2Gi"
password: "my-password"
acceptLicenseAgreement: "yes"
volumes:
data:
mode: "dynamic"
# Only used if mode is set to "dynamic"
# Dynamic provisioning using the provided storageClass
dynamic:
storageClassName: "neo4j"
accessModes:
- ReadWriteOnce
requests:
storage: 100Gi
You need a minimum of 3 core nodes to create a cluster. So you must run the helm install command 3 times for the neo4j-cluster-core helm chart.
Successful Cluster Creation
kubectl -n neo4j-cluster exec neo4j-cluster-0 -- tail /logs/neo4j.log
2022-03-29 19:14:55.139+0000 INFO Bolt enabled on [0:0:0:0:0:0:0:0%0]:7687.
2022-03-29 19:14:55.141+0000 INFO Bolt (Routing) enabled on [0:0:0:0:0:0:0:0%0]:7688.
2022-03-29 19:15:09.324+0000 INFO Remote interface available at http://localhost:7474/
2022-03-29 19:15:09.337+0000 INFO id: E2E827273BD3E291C8DF4D4162323C77935396BB4FFB14A278EAA08A989EB0D2
2022-03-29 19:15:09.337+0000 INFO name: system
2022-03-29 19:15:09.337+0000 INFO creationDate: 2022-03-29T19:13:44.464Z
2022-03-29 19:15:09.337+0000 INFO Started.
2022-03-29 19:15:35.595+0000 INFO Connected to neo4j-cluster-3-internals.neo4j-cluster.svc.cluster.local/10.233.125.2:7000 [RAFT version:5.0]
2022-03-29 19:15:35.739+0000 INFO Connected to neo4j-cluster-2-internals.neo4j-cluster.svc.cluster.local/10.233.127.2:7000 [RAFT version:5.0]
2022-03-29 19:15:35.876+0000 INFO Connected to neo4j-cluster-3-internals.neo4j-cluster.svc.cluster.local/10.233.125.2:7000 [RAFT version:5.0]
Install Read Replica
The cluster must be up and functioning to install the read replica.
I provide the -n with a namespace and the –create-namespace tag because it allows me to install my helm release in this case neo4j-1 into its own namespace. Which helps with operations for DR, Backup and even lifecycle cleanup down the road. When installing a cluster all the helm releases must be in the same namesapce.
Start Graph Databasing!
As you can see there are plenty of tutorials to see how you may use Neo4j
This week Portworx Enterprise 2.9.0 released with it comes support for K8s 1.22 and the new Essentials for FlashArray License. You can now have more nodes and capacity and as many clusters as you like. Previously you only got 5 nodes and a single cluster for PX Essentials. More info in the release notes:
While creating the spec you will get the commands to run with kubectl to create the px-pure-secret. This secret takes the pure.json file and puts it in a place where the Portworx Installer will use it to provision it’s block devices from FlashArray. How to create the pure.json file? More info here: https://docs.portworx.com/cloud-references/auto-disk-provisioning/pure-flash-array/#deploy-portworx
Apply the Operator and the Storage Cluster. Enjoy your new data platform for Kubernetes.
When Portworx detects the drives are coming from a FlashArray the License is automatically set! Nothing special to do!
Watch the walkthrough
PX + FA = ❤️
First, the ability to use Portworx with FlashArray is not new with 2.9.0. What is new is the automatic Essentials license. Of course you would have benefits of upgrading Essentials to Enterprise to get DR, Autopilot and Migration. Why would you want to run Portworx on the FlashArray? The central storage platform from the FlashArray give all the benefits you are used to with Pure but to your stateful workloads. All Flash Performance. No disruptive upgrade everything. Evergreen. Dedupe and compression with no performance impact. Thin provisioning. Put it this way? The same platform you run baremetal and vm based business critical apps? Oracle, MS SQL?Shouldn’t it run your modernized cloud native versions of these applications? (Still can be containerized Oracle or SQL so don’t @ me.) Together with Portworx it just makes sense to be better together.
PX + FB = ❤️
Don’t get confused. While the PX Store layer needs block storage to run, FlashBlade and Portworx has already been supported as a Direct Attach target for a while now. You may even notice in the demo above my pure.json includes my FlashBlade. So go ahead use them all.
Over a year a go we were working on the final parts of the acquisition of Portworx. I knew Portworx was going to change everything at Pure. I also expected it to take a while. I knew that we were going to see amazing new things built on this Cloud Native Data Platform. In the last year I have witnessed customers do just that with their own stateful workloads. Examples include banks, online gaming, SaaS providers, retail chains and many more.
What I also knew would come someday was Portworx Data Services would introduce all of us a way to have stateful workloads as a service. Database as a service, anywhere k8s can run, on any cloud. On Tanzu, AWS, Azure, Google, RedHat, Rancher and so many more. Your data managed but not locked into a proprietary platform. Managed in a way built for Cloud Native, Built for Kubernetes. It is also here way faster than I thought. A big thank you to our Engineering teams for the amazing work to make Portworx Data Services a real thing.
More than just a deployment tool
This is not just “deploy me a container” with a database. This is a managed experience with the day 2 operations built in. You can work on getting results from your data while PDS manages the performance, protection and availability of your solution wherever you want it to be. Not locked to specific cloud but anywhere that runs K8s.
But Doesn’t Operator XYZ do that?
Maybe. A little bit. Today’s developers expect to choose the tools they need to deliver their application. Not to be forced onto a single platform. This results in Database Administrators and DevOps teams supporting many different data services all with their own nuances. Some places have 10-15 different databases or data services (some of them are not really databases). Imagine having to support, the deployment and ongoing management of everyone of those, in most cases the with no extra time or resources. Normally you don’t get a new headcount every time a developer wants to use a new kind of data service.
Portworx Data Services lets you learn one API, one Interface and you get one vendor to support and manage the little things you don’t have time for, like Performance, High Availability and Disaster Recovery best practices. Making the data available in other sites or clouds for analytics or other use cases. Even Building that data into Dev-Test-QA workflows.
Getting Started with Portworx 2.8 and the FlashArray and FlashBlade
Last week Portworx 2.8 went GA, with it new support for Tanzu TKGs TKGm (We supported PKS/TKGi for a long time), but also Support for Cloud Drives for FlashArray and Direct Access for FlashBlade. It also simplified the installation of Portworx with Tanzu from this earlier version.
FlashArray Volumes for Portworx
Portworx will automate creating a storage pool from volumes provisioned from the FlashArray. This is done for your during the install, you may specify the size of the volumes in the spec generator at https://central.portworx.com
Process to install
NOTE as of 8/4/21: This feature is in Tech Preview (contact me if you want to run in Production)
Create the px-pure-secret from the pure.json file
Generate your Portworx Cluster spec from https://central.portworx.com
Install the PX-Operator (command at the end of the spec generator).
Install the Portworx Storage Cluster
https://docs.portworx.com/reference/pure-json-reference/ Also look that the pure.json reference in order to get the API key and token in a secret for you to use with Portworx. The installation of Portworx detects this Kubernetes secret and uses that information to provision drives from the array. Check out the youtube demo:
Remember the secret must be called px-pure-secret and be in the namespace that you install Portworx.
Select Pure FlashArray
2. Generate the spec for the Portworx Cluster.
3. Install the PX-Operator – I suggest using what you get from the Spec generator online or down to a local file.
kubectl apply -f pxoperator.yaml
4. Install the Storage Cluster
kubectl apply -f px-spec.yaml
For FlashBlade!
Also included in the pure.json is the API Token and IP information for my FlashBlade. Since the FlashBlade runs NFS the K8s node mounts it directly. We call with Direct Attach and allows you to leverage your FlashBlade for data that may exist outside of the PX-Cluster. Watch the demo to see it in action. Create a StorageClass for FlashBlade and a PVC using that class. Portworx automates the rest. More info: https://docs.portworx.com/portworx-install-with-kubernetes/storage-operations/create-pvcs/pure-flashblade/
First, this process works today on clusters made with the TKG tool that does not use the embedded management cluster. For clarity I call those clusters TKC or TKC Guest Clusters. The run as VM’s. You just can’t add block devices outside of the Cloud Native Storage (VMware’s CSI Driver). At least I couldn’t.
Now TKG deploys using a Photon 3.0 template. When I wrote this blog and recorded the demo the current latest version is TKG 1.2.1 and the k8s template is 1.19.3-vmware.
First generate base64 encoded versions of your user and password to vCenter.
# Update the following items in the Secret template below to match your environment:
VSPHERE_USER: Use output of printf <vcenter-server-user> | base64
VSPHERE_PASSWORD: Use output of printf <vcenter-server-password> | base64
The vsphere-secret.yaml save this to a file with your own user and password to vCenter (from above).
kubectl apply the above spec after you update the above template with your user and password.
Follow these steps:
# create a new TKG cluster
tkg create cluster tkg-portworx-cluster -p dev -w 3 --vsphere-controlplane-endpoint-ip 10.21.x.x
# Get the credentials for your config
tkg get credentials tkg-portworx-cluster
# Apply the secret and the operator for Portworx
kubectl apply -f vsphere-secret.yaml
kubectl apply -f 'https://install.portworx.com/2.6?comp=pxoperator'
#generate your spec first, you get this from generating a spec at https://central.portworx.com
kubectl apply -f tkg-px.yaml
# Wait till it all comes up.
watch kubectl get pod -n kube-system
# Check pxctl status
PX_POD=$(kubectl get pods -l name=portworx -n kube-system -o jsonpath='{.items[0].metadata.name}')
kubectl exec $PX_POD -n kube-system -- /opt/pwx/bin/pxctl status
You can now create your own or use the premade storageClass
kubectl apply -f https://raw.githubusercontent.com/2vcps/quake-kube/master/example.yaml
deployment.apps/quakejs created
service/quakejs created
configmap/quake3-server-config created
persistentvolumeclaim/quake3-content created
k get pod
NAME READY STATUS RESTARTS AGE
quakejs-668cd866d-6b5sd 0/2 ContainerCreating 0 7s
k get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
quake3-content Bound pvc-6c27c329-7562-44ce-8361-08222f9c7dc1 10Gi RWO px-db 2m
k get pod
NAME READY STATUS RESTARTS AGE
quakejs-668cd866d-6b5sd 2/2 Running 0 2m27s
k get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 100.64.0.1 <none> 443/TCP 20h
quakejs LoadBalancer 100.68.210.0 <pending> 8080:32527/TCP,27960:31138/TCP,9090:30313/TCP 2m47s
Now point your browser to: http://<some node ip>:32527 Or if you have the LoadBalancer up and running go to the http://<Loadbalancer IP>:8080
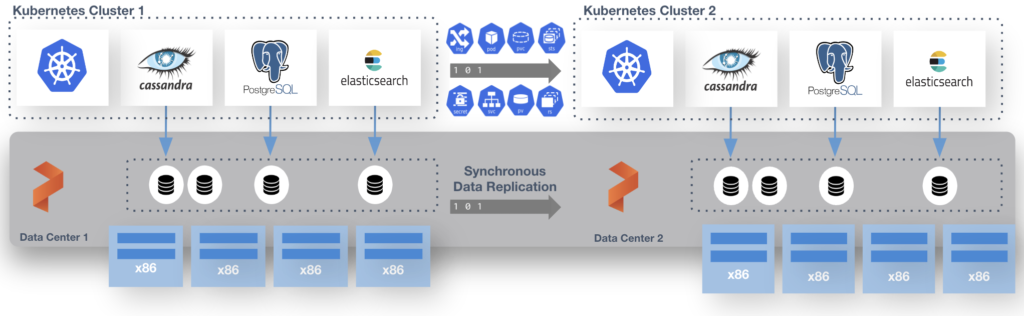
For the demo I have 2 Kubernetes clusters with a single stretched Portworx cluster in AWS. This allows Metro DR to mirror the data between the 2 clusters so if there is a complete loss of Cluster 1 the application can be restarted with no loss of data.
You can have active workloads on both clusters. Just FYI.
Lots of new things to learn over the last month. I wanted to present everyone with my first demo with #portworxbypure. The official documentation is here. Always read the docs on how to set it up.
For the demo I have 2 Kubernetes clusters with a single stretched Portworx cluster in AWS. This allows Metro DR to mirror the data between the 2 clusters so if there is a complete loss of Cluster 1 the application can be restarted with no loss of data. The ELB in Amazon can be set to provide little interaction when getting your app back up and working, for this demo I tell the the deployment to fail over. Sort of the big red button for failover. Like all the things Cloud Native this can be automated.
Please check out this demo on YouTube and let me know what you think.
There are of course many options when it comes to how your app will work and this is for a basic web frontend and database. Scale out databases can be treated different. It all depends on how your application is architected and what the DR requirements will be.