First, if you are using Pure Storage and Kubernetes make life easier and take a look at our plugin. Now version 1.2.2 and GA.
https://hub.docker.com/r/purestorage/k8s/
Make sure the follow the directions on the page to pull and install the plugin. If you are using Openshift pay special attention to the Readme. I will post more on this in the near future.
Cockroach DB as our Persistent Database
I want to simulate a very easy database that I can easily use in a container. That is also not the same old. I built a Go app that will write to a database over and over to kind of demonstrate the inner workings of the plugin but not necessarily supply a performance test.
To learn more about the steps I use in the video to deploy and manage CRDB in K8s please check out this link. https://www.cockroachlabs.com/docs/stable/orchestrate-cockroachdb-with-kubernetes.html
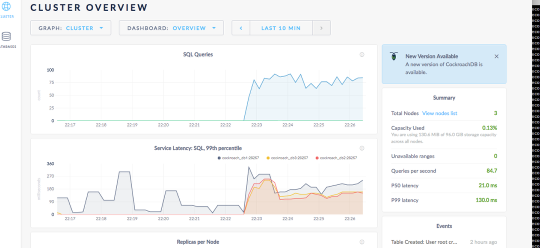
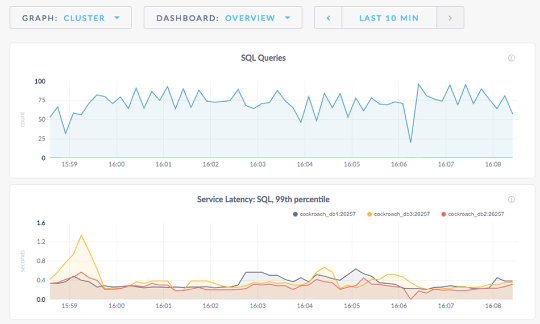
With that said, please check out how to deploy and scale a database with a persistent data platform from a Pure FlashArray. Watch this in Full screen to make the CLI commands easier to see.
What you are seeing in the video:
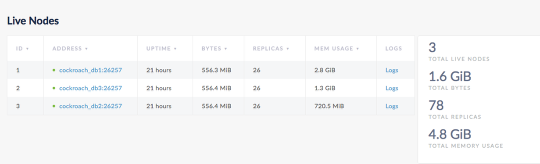
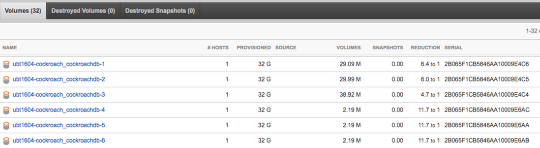
- Deploy the initial 3 pods with volumes automatically created and connected on the Pure FA.
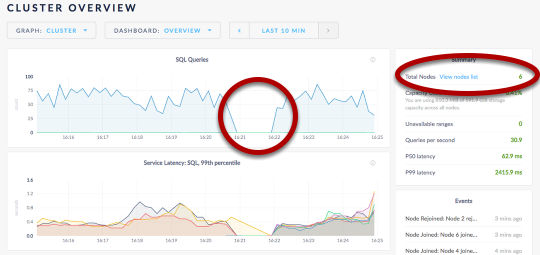
- Initialize the cluster.
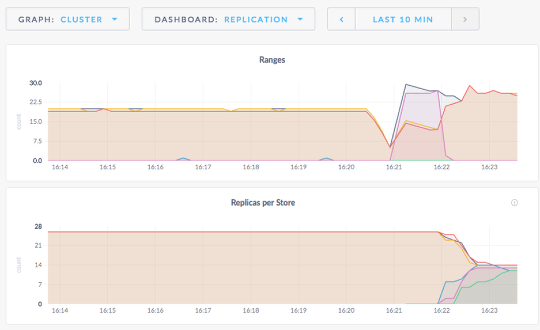
- Fail a node and watch K8s redeploy a new container and re-attach the data volume.
- Run a load generation application as a K8s Job.
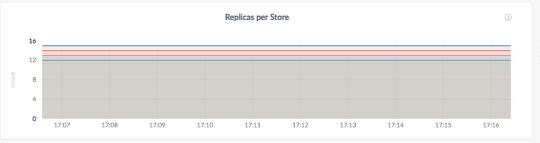
- Scale the DB cluster out to 8 nodes.
What is next?
This is a really easy and quick demo but it show the ease of using the Pure Plugin to manage the persistent data, making sure you do not lose data in the event of app crashes. Also easily scaling. This can all be done via policy and the deployment can be made even easier using Helm. In a future post we will see how we can take advantage of these methods and keep the same highly available, high performance and very easy to use persistent data platform for your application.